Why Traces?
Traces are a way to capture the full context of an agent’s interaction with a user. They are a powerful tool for debugging and understanding the behavior of your agent.
Quotient captures traces to provide you with information for debugging and understanding the behavior of your agent, and also to help you automatically understand how people are using your agent with Quotient Reports.
Traces and Spans
Traces represent a single end-to-end interaction with an agent. Traces are made up of Spans, which represent a unit of work within the overall interaction. We integrate with OpenInference for OpenTelemetry instrumentation, to automatically capture traces for different LLM providers and agent frameworks.
We use the OpenInference semantic conventions — standardized naming across frameworks — for the trace data, and also have our own semantic conventions specifically for vector databases.
Follow the example below to see how you can get started.
Initialize the Tracer
Initialize the Quotient tracer with configuration settings for your application:
from quotient import Quotient
quotient = Quotient()
quotient.tracer.init(
app_name="my-first-app",
environment="dev",
# optional: run detections on your traces
detections=[DetectionType.HALLUCINATION, DetectionType.DOCUMENT_RELEVANCY],
)
Parameters:
app_name (string): Name of your application. Core parameter used to identify the source of logs in the Quotient dashboard.environment (string): Environment where your application is running (e.g., “dev”, “staging”, “prod”). Core parameter used to help segregate logs by deployment environment.detections (array): List of detection types to run. Available options:
DetectionType.HALLUCINATION - Detects potential hallucinations in model outputsDetectionType.DOCUMENT_RELEVANCY - Evaluates how relevant retrieved documents are to the user query
Send Traces
We provide a decorator to trace agent interactions. The decorator will automatically capture the agent’s input, output, tool calls, and any relevant context.
You can find examples below for how we integrate for different frameworks.
Agent SDKs
Agno
To start tracing Agno agents, you need the following minimum dependencies:
pip install "quotientai>=0.4.6" "agno>=1.5.2" "openinference-instrumentation-agno==0.1.10"
export OPENAI_API_KEY=your-api-key
export QUOTIENT_API_KEY=your-api-key
# setup the quotient tracer
from openinference.instrumentation.agno import AgnoInstrumentor
from quotientai import QuotientAI
quotient = QuotientAI()
quotient.tracer.init(
app_name="agno-search-app",
environment="dev",
instruments=[AgnoInstrumentor()],
)
# setup your agno agent with the Quotient tracer
from agno.agent import Agent
from agno.models.openai import OpenAIChat
from agno.tools.duckduckgo import DuckDuckGoTools
@quotient.trace('agno-agent-ddgs-search')
def run_agno():
"""
This is your main function. You can add @quotient.trace() to whatever the equivalent main entrypoint
is in your application.
"""
agent = Agent(
model=OpenAIChat(id="gpt-4o-mini"),
tools=[DuckDuckGoTools()],
markdown=True,
)
agent.print_response("What is currently trending in AI?")
if __name__ == "__main__":
run_agno()
OpenAI Agents SDK
To start tracing OpenAI Agents, you need the following minimum dependencies:
pip install "quotientai>=0.4.6" "openai-agents>=0.1.0" "openinference-instrumentation-openai-agents==1.1.1"
export OPENAI_API_KEY=your-api-key
export QUOTIENT_API_KEY=your-api-key
quotient_trace_openai_agents.py
# setup the quotient tracer
from openinference.instrumentation.openai_agents import OpenAIAgentsInstrumentor
from quotientai import QuotientAI
quotient = QuotientAI()
quotient.tracer.init(
app_name="openai-agents-search-app",
environment="dev",
instruments=[OpenAIAgentsInstrumentor()],
)
# setup your openai agents with the Quotient tracer
import asyncio
from agents import Agent, Runner
@quotient.trace('haiku-agent')
async def main():
"""
This is your main function. You can add @quotient.trace() to whatever the equivalent main entrypoint
is in your application.
"""
agent = Agent(
name="haiku-assistant",
instructions="You only respond in haikus.",
)
result = await Runner.run(agent, "Tell me about recursion in programming.")
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
LangGraph
To start tracing LangGraph agents, you need the following minimum dependencies:
pip install "quotientai>=0.4.6" "langgraph>=0.1.6" "openinference-instrumentation-langchain==0.1.1"
export ANTHROPIC_API_KEY=your-api-key
export QUOTIENT_API_KEY=your-api-key
quotient_trace_langgraph.py
# setup the quotient tracer
from openinference.instrumentation.langchain import LangChainInstrumentor
from quotientai import QuotientAI
quotient = QuotientAI()
quotient.tracer.init(
app_name="langgraph-weather-app",
environment="dev",
instruments=[LangChainInstrumentor()],
)
# setup your langgraph agent with the Quotient tracer
from langgraph.prebuilt import create_react_agent
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"It's always sunny in {city}!"
@quotient.trace('langgraph-weather-agent')
def main():
"""
This is your main function. You can add @quotient.trace() to whatever the equivalent main entrypoint
is in your application.
"""
agent = create_react_agent(
model="anthropic:claude-3-7-sonnet-latest",
tools=[get_weather],
prompt="You are a helpful assistant"
)
agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]}
)
if __name__ == "__main__":
main()
Smolagents
To start tracing Smolagents agents, you need the following minimum dependencies:
pip install "quotientai>=0.4.6" "smolagents>=1.15.0" "openinference-instrumentation-smolagents==0.1.14"
export OPENAI_API_KEY=your-api-key
export QUOTIENT_API_KEY=your-api-key
quotient_trace_smolagents.py
# setup the quotient tracer
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
from quotientai import QuotientAI
quotient = QuotientAI()
quotient.tracer.init(
app_name="smolagents-weather-app",
environment="dev",
instruments=[SmolagentsInstrumentor()],
)
# setup your smolagents agent with the Quotient tracer
import requests
from smolagents import ToolCallingAgent, LiteLLMModel, tool
@tool
def search_wikipedia(query: str) -> str:
"""
Fetches a summary of a Wikipedia page for a given query.
Args:
query: The search term to look up on Wikipedia.
Returns:
str: A summary of the Wikipedia page if successful, or an error message if the request fails.
Raises:
requests.exceptions.RequestException: If there is an issue with the HTTP request.
"""
url = f"https://en.wikipedia.org/api/rest_v1/page/summary/{query}"
try:
response = requests.get(url)
response.raise_for_status()
data = response.json()
title = data["title"]
extract = data["extract"]
return f"Summary for {title}: {extract}"
except requests.exceptions.RequestException as e:
return f"Error fetching Wikipedia data: {str(e)}"
@quotient.trace('smolagents-wikipedia-agent')
def main():
"""
This is your main function. You can add @quotient.trace() to whatever the equivalent main entrypoint
is in your application.
"""
model = LiteLLMModel(model_id="gpt-4o")
agent = ToolCallingAgent(
tools=[search_wikipedia],
model=model,
)
agent.run("What happened in the 2024 US election?")
if __name__ == "__main__":
main()
Other Frameworks
For tracing other frameworks using OpenInference, please refer to the OpenInference Instrumentation repository on GitHub, and use the appropriate instrumentor for your framework.
Remember to add the appropriate instrumentor for your framework to the instruments list when initializing the Quotient tracer, and check the minimum required dependencies for your frameworks instrumentation library.
Tracing without OpenInference
If you are not using OpenInference, you can still trace your agents using other instrumentation libraries, however, note that you maybe not be able to leverage features we build on top of traces such as Detections, Reports, and Steering.
Example: Tracing an OpenAI Agent in a Streaming API application
For agents that are wrapped in a backend API framework (e.g. FastAPI), async + streaming responses are handled differently than in a standalone agent application in that tokens are streamed via an async Python generator. When this is the case, you need to use the use_span context manager to ensure that all operations within the context are part of the same trace.
Below you can find an example of how to do this with an OpenAI Agent in a FastAPI streaming application.
pip install "quotientai>=0.4.10" "openai-agents>=0.1.0" "openinference-instrumentation-openai-agents==1.1.1" "fastapi>=0.115.6" "uvicorn>=0.34.0"
import asyncio
import json
from agents import Agent, Runner
from openai.types.responses import ResponseTextDeltaEvent
from openinference.instrumentation.openai_agents import OpenAIAgentsInstrumentor
from opentelemetry.trace import get_tracer, use_span
from quotientai import QuotientAI
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
import uvicorn
# Initialize Quotient AI with OpenAI Agents instrumentation
quotient = QuotientAI()
quotient.tracer.init(
app_name="joker-agent",
environment="dev",
instruments=[OpenAIAgentsInstrumentor()]
)
agent = Agent(
name="Joker",
instructions="You are a helpful assistant.",
)
app = FastAPI()
@app.post("/generate-jokes")
async def my_endpoint():
# 1️⃣ start the root span
root_span = quotient.tracer.start_span('joker-agent')
# 2️⃣ make the span current for all operations within the context
stream_ctx = use_span(root_span, end_on_exit=False)
async def my_generator():
# 3️⃣ capture all the returned events within the context
with stream_ctx:
# Your AI agent logic here, in this case we are using an OpenAI Agent
# This could be calling OpenAI, LangChain, or any other AI service
my_stream = Runner.run_streamed(agent, input="Please tell me 5 jokes.")
async for event in my_stream.stream_events():
if event.type == "raw_response_event" and isinstance(event.data, ResponseTextDeltaEvent):
yield f"data: {json.dumps({'content': event.data.delta})}\n\n"
# 4️⃣ end the span and flush the trace after the context is exited
root_span.end()
quotient.force_flush()
return StreamingResponse(
my_generator(),
media_type="text/plain"
)
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
Key Components Explained:
- Root Span:
quotient.tracer.start_span() creates the main span that will contain all child operations
- Context Management:
use_span(root_span, end_on_exit=False) makes the span current for all operations within the context
- Streaming: The generator function handles the streaming response while maintaining trace context
- Cleanup:
root_span.end() and quotient.force_flush() ensure traces are properly closed and sent
View Traces
You can view traces in the Quotient Web UI by clicking on the “Traces” tab, and selecting your app_name and environment as well as time range.
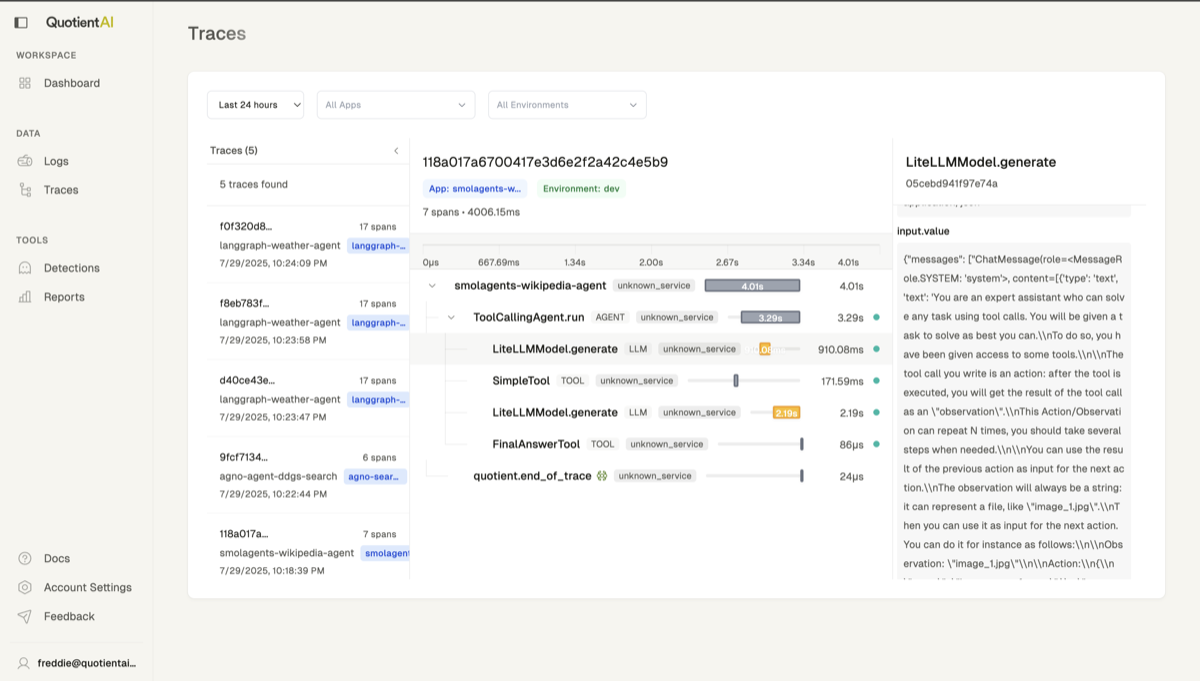
Adding Custom Spans
You can also add custom spans to traces to capture additional information with start_span or the OpenTelemetry get_current_span method.
from opentelemetry.trace import get_current_span
from quotientai import QuotientAI
from quotientai.tracing import start_span
quotient = QuotientAI()
quotient.tracer.init(
app_name="my-app",
environment="dev",
)
@quotient.trace('smolagents-wikipedia-agent')
def main():
"""
This is your main function. You can add @quotient.trace() to whatever the equivalent main entrypoint
is in your application.
"""
# start a custom span
with start_span('custom-span'):
# do something
span = get_current_span()
span.set_attribute('custom_attribute', 'custom_value')
# do something else
span = get_current_span()
span.set_attribute('custom_attribute', 'custom_value')
# do something else
if __name__ == "__main__":
main()
Vector Database Semantic Conventions
We have our own semantic conventions for vector databases to help you understand how vector databases are being used.
We currently support instrumenting the following vector databases:
Basic Usage
from quotientai import QuotientAI, ChromaInstrumentor, PineconeInstrumentor, QdrantInstrumentor
# Initialize QuotientAI client
quotient = QuotientAI()
# Initialize tracing with vector database instrumentors
quotient.tracer.init(
app_name="my-app",
environment="production",
instruments=[
ChromaInstrumentor(),
PineconeInstrumentor(),
QdrantInstrumentor(),
],
)
Common Attributes
| Attribute | Type | Description | Example |
|---|
db.system.name | string | Vector database system name | "chroma", "pinecone", "qdrant" |
db.operation | string | Database operation type | "query", "add", "upsert", "delete" |
db.collection.name | string | Collection/index name | "user_profiles" |
db.operation.status | string | Operation status | "completed", "error" |
db.ids_count | int | Number of IDs processed | 150 |
db.vector_count | int | Number of vectors processed | 320 |
db.n_results | int | Number of results returned | 15 |
db.query.retrieved_documents | string | JSON string of retrieved documents | [{"id": "doc1", "score": 0.95, ...}] |
Database-Specific Attributes
ChromaDB
db.documents_count: Number of documents processeddb.metadatas_count: Number of metadata entriesdb.filter: Applied filters (JSON string)db.where_document: Document filter conditions
Pinecone
db.index.name: Index namedb.index.dimension: Index dimensiondb.create_index.metric: Distance metric useddb.create_index.spec: Index specificationsdb.query.namespace: Query namespacedb.delete_all: Whether all records are deleteddb.update.id: ID being updateddb.update.metadata: Metadata being updated
Qdrant
db.collection.dimension: Collection dimensiondb.limit: Query limitdb.offset: Query offsetdb.filter: Applied filters (JSON string)db.operation.id: Operation ID for async operations
The db.query.retrieved_documents attribute contains a JSON string with the following structure:
[
{
"document.id": "doc123",
"document.score": 0.95,
"document.content": "document text content",
"document.metadata": "{\"source\": \"web\", \"category\": \"tech\"}"
}
]
Error Handling
All instrumentors gracefully handle missing dependencies:
- If a vector database library is not installed, the instrumentor will log a warning and skip instrumentation
- If instrumentation fails, the original functionality is preserved
- Errors during operation tracing are logged but don’t affect the underlying operation
Get Traces Programmatically
You can use the Quotient Python SDK to get traces programmatically. Currently we only support getting a single trace via it’s ID.
from quotientai import QuotientAI
quotient = QuotientAI()
trace = quotient.traces.get(trace_id="123")
print(trace)
# Trace(id="123", ...)