What are Detections?
Detections are asynchronous processes that run when you send logs or traces to Quotient. They are used to automatically detect issues with hallucinations, document relevancy, context usage, and other reliability issues. Detections are run in the background, and you can poll for results using the Quotient SDK.Initialize the Logger with Detections
Send Logs with Detections Enabled
Poll for Detections
Synchronously poll for detection results using the client:Parameters:
log_id(string): The log ID of the log you want to poll for detections.timeout(int): The maximum time to wait for a response in seconds. Defaults to 300.poll_interval(float): The interval between checks in seconds. Defaults to 2.0.
Returns:
Log(object): ALogobject containing the following fields:id(string): Unique identifier for the log entry.app_name(string): Name of the application that generated the log.environment(string): Environment where the log was generated (e.g., “dev”, “prod”).detections(array): List of detection types that were configured for this log.detection_sample_rate(float): Sample rate used for detections on this log.user_query(string): The original user query or prompt that was logged.model_output(string): The model’s response that was logged.documents(array): List of documents used as context for the model. Can be strings or LogDocument objects.message_history(array): Previous messages in the conversation, following the OpenAI message format.instructions(array): List of instructions provided to the model.tags(object): Dictionary of tags associated with the log entry.created_at(datetime): Timestamp when the log was created.status(string): Current status of the log entry.has_hallucination(boolean): Whether the model output was detected to contain hallucinations.doc_relevancy_average(float): Average relevancy score for the documents provided.updated_at(datetime): Timestamp when the log was last updated.evaluations(array): List of evaluation results for the log entry.
Detections Dashboard
Go to the Detections Dashboard to see your logs and any detected hallucinations.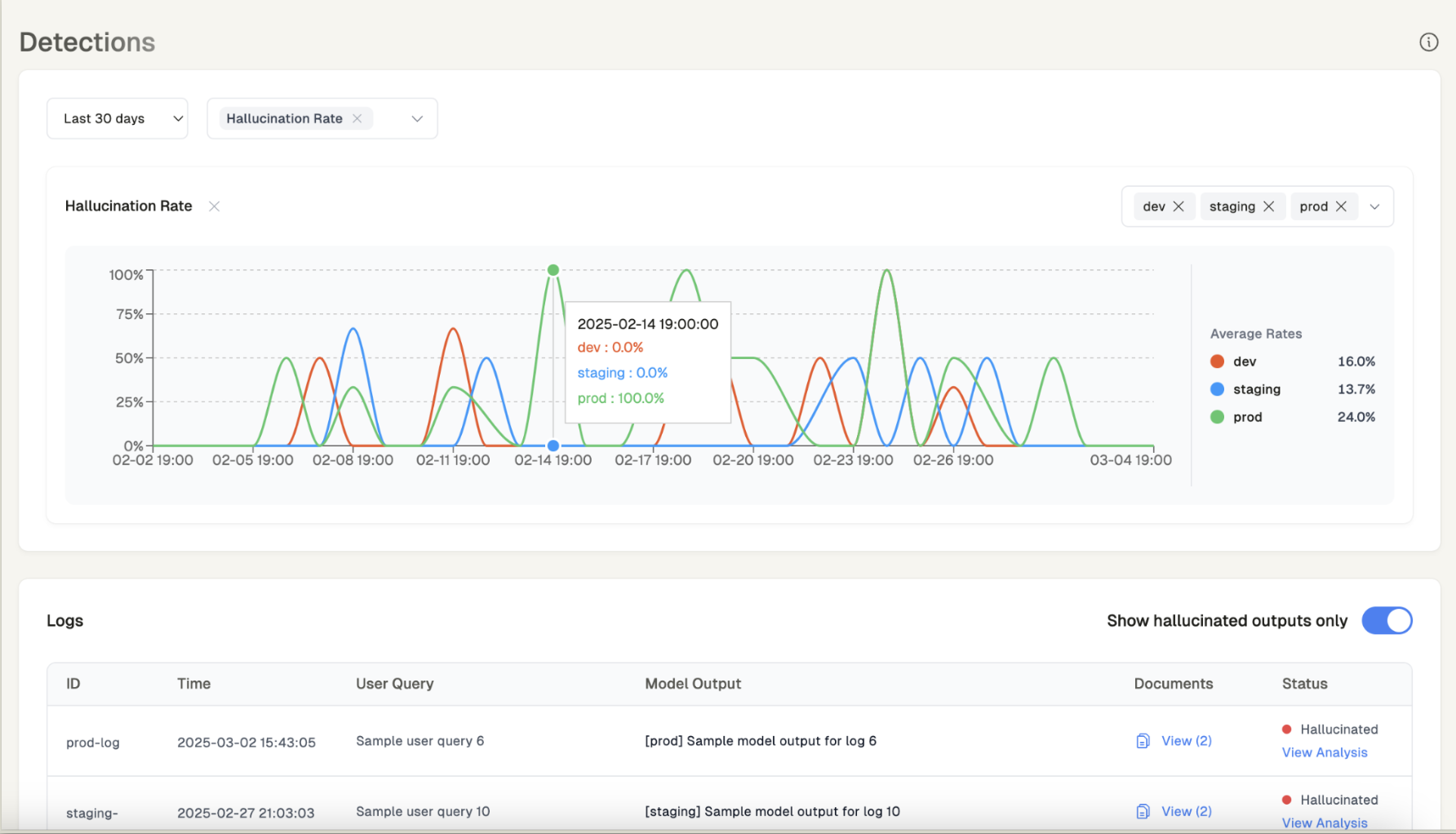
Hallucinations
How do we define hallucinations?
The hallucination rate measures how often a model generates information that cannot be found in its provided inputs, such as retrieved documents, user messages, or system prompts. Quotient reports an extrinsic hallucination rate: we determine whether the model’s output is externally unsupported by the context it was given.What is an Extrinsic Hallucination?
What is an Extrinsic Hallucination?
How do we detect hallucinations?
- Break output into individual claims or sentences
- Compare each claim to available context, including:
user_query(what the user asked)documents(retrieved evidence)message_history(prior turns in the conversation)
- Flag claims that lack support in any of the above inputs as hallucinations
Why is it important to monitor your AI system for hallucinations?
Extrinsic hallucinations are the primary failure mode in augmented AI systems. Even when retrieval succeeds, generation can drift. This metric helps teams:- Catch hallucinations early in development
- Monitor output quality post-deployment
- Guide prompt iteration and model fine-tuning
Document Relevance
How do we define document relevance?
Document Relevance measures how well your retrieval or search system finds context that’s actually useful for answering the user’s query. Specifically, it quantifies how relevant the retrieved documents (or chunks) are to what the user asked. A document is considered relevant if it contains information that addresses at least one part of the query. If it does not address any part, it is marked as irrelevant. The Document Relevance score is calculated as the fraction of documents that are relevant to at least one part of the user query.How do we measure document relevance?
- Compare each document (or chunk) against the full
user_query. - Determine whether the document contains information relevant to any part of the query:
- If it does, mark it as
relevant - If it doesn’t, mark it as
irrelevant
- If it does, mark it as
- Compute the overall document relevance score as:
relevant_documents / total_documents.
Why is it important to monitor document relevance?
Document Relevance is a core metric for evaluating search- and retrieval-augmented systems. Even if the AI model generates well, weak retrieval can negatively impact the quality of the response. This metric helps teams:- Assess whether retrieval is surfacing useful context
- Debug cases where generation fails despite successful prompting
- Improve recall/precision of retrieved results
- Monitor drift after retriever or data changes